
O que é ciência de dados? Qual o perfil e as competências do cientista envolvido nesse novo paradigma?
Por Sérgio Mariano Dias, com colaboração de Gustavo Torres e Marcelo Pita, da divisão de Soluções Analíticas no Data Lake —11 de dezembro de 2017
O “quarto paradigma” da ciência [1], a profissão mais “sexy” do século 21 [2], uma nova buzz word! A ciência de dados emerge do fato de os dados estarem em toda parte. Dados provenientes de interações sociais, governo eletrônico, atividades empresariais nos mais diversos setores, conhecimento científico em biologia, química etc., estão sendo gerados continuamente, e em enorme quantidade, todos os dias. Existe um volume tão grande de dados que é cada vez mais difícil localizar e extrair o conhecimento do qual se necessite.
“Nova” área tecnológica
A partir da necessidade de análise desse emaranhado de dados, surgiu uma “nova” área tecnológica, a chamada ciência de dados. De forma interdisciplinar, ela faz uso de estatística, matemática, programação, inteligência artificial, aprendizado de máquina, mineração de dados e outras tantas técnicas para extração de conhecimento de bases de dados. Lidando com dados estruturados e não estruturados, é uma área que compreende todos os aspectos relacionados à limpeza, preparação e análise para obtenção de insights e conhecimentos necessários para tomada de decisão baseada em evidência.
Ademais, plataformas de ciências de dados devem estar preparadas para, potencialmente, lidar com grandes volumes de dados. Note que, apesar do termo ciência de dados ser relativamente novo, as atividades executadas pelo “cientista de dados” são bastante antigas [3], obviamente respeitadas as diferenças históricas no que diz respeito às necessidades atuais de big data (volume, variedade, veracidade, velocidade e valor).
Mas quem é o cientista de dados?
Josh Wills, em 2012, à época diretor de engenharia de dados na Cloudera, publicou um tweet bem humorado definindo o cientista de dados, o que representava (e ainda representa) o senso comum a respeito deste profissional: “Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician”. Em português: “Cientista de dados (subst.): Pessoa que é melhor em estatística do que qualquer engenheiro de software e melhor em engenharia de software do que qualquer estatístico”. Em certo sentido, Josh estava certo, na visão prática de um executivo. Porém, de lá para cá, as habilidades requeridas para um cientista de dados começaram a ficar mais claras.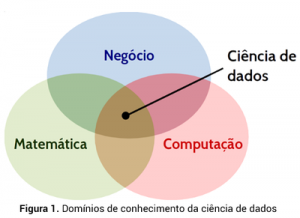

A Figura 1 ilustra as competências esperadas para a realização de ciência de dados, quais sejam, ciência da computação, matemática e negócio.
Note que o domínio do negócio e as habilidades em ciências da computação permitem ao cientista de dados realizar o processamento de grandes volumes de dados. De forma similar, o conhecimento em ciência da computação e matemática permitem ao cientista de dados trabalhar com aprendizado de máquina. Por último, o conhecimento em matemática e o domínio do negócio permitem ao profissional aplicar técnicas de estatística para análise dos dados. Como interseção dessas diferentes áreas do conhecimento tem-se o cientista de dados.
Na prática, raramente (diga-se: “nunca”) encontramos um profissional que domine todas essas habilidades em profundidade. Desta forma, projetos em ciência de dados são executados por equipes interdisciplinares, nas quais diferentes papéis dominam, em maior profundidade, determinado assunto. Entretanto, faz-se necessário o conhecimento das ferramentas, técnicas e tecnologias que permeiam todas as áreas. Tomemos como exemplo o conhecimento em estatística para um cientista de dados com formação primária em ciência da computação. O ferramental estatístico permite a comparação de diferentes modelos concebidos para determinado problema em análise. De forma semelhante, o conhecimento em estatística proporciona ao cientista de dados com ênfase no domínio do negócio argumentar, com um índice de confiança, que determinada ação baseada em evidência pode ser adotada.
Posturas básicas de um cientista de dados
Cientistas de dados devem ter um entendimento do domínio do problema (negócio), além de saber aplicar práticas de gerenciamento de dados. Também devem desenvolver o raciocínio analítico sob diferentes perspectivas e classes de problemas para a formulação de questões e hipóteses apropriadas em ciência de dados. Outros saberes relevantes envolvem a aplicação de técnicas e ferramentas e a validação dos modelos de análise construídos. Por fim, acrescente-se a postura de propor, documentar e adaptar processos de decisão em conformidade com os modelos concebidos.
Habilidades técnicas requeridas por um cientista de dados
Destaca-se o conhecimento de lógica de programação e proficiência em alguma linguagem — a habilidade de programação é fundamental para este cientista. Ademais, dominar linguagens de programação como R, Python, Julia, Scala, C, C++ e/ou Java é essencial.
Dentre as diversas linguagens de programação disponíveis, sem dúvidas, duas se destacam. A primeira é Python, linguagem de programação de uso geral, que possui diversas bibliotecas para ciência de dados. A segunda é R, uma linguagem de programação estatística. R possui a maior variedade de técnicas, está em constante evolução e, finalmente, encontra-se disponível nas principais soluções comerciais para análise de dados (SAS, IBM SPSS, Microstrategy, Rapidminer, Knime etc.).
Não podemos esquecer ainda o âmbito do armazenamento e processamento de grandes volumes de dados. Essencialmente, a ciência de dados lida com dados organizados em diferentes formatos e em grande quantidade. Neste cenário, o domínio de algumas tecnologias é essencial. Dentre elas destacamos: HDFS, Hadoop, Hive, Impala, Spark, Mahout.
Processos Executados pelo Cientista de Dados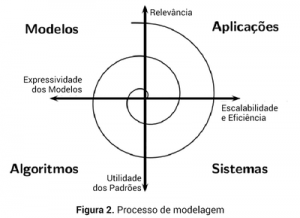
Cientistas de dados lidam com grandes volumes de dados para conceber modelos matemáticos que expressam comportamentos presentes nos dados. A figura 2 ilustra esse processo [4]. Nos quadrantes tem-se modelos, algoritmos, sistemas e aplicações. Nos eixos relevância, expressividade dos modelos, utilidade dos padrões e escalabilidade e eficiência. Partindo da necessidade de uma aplicação (demanda de negócio) gera-se um modelo. Para conceber o modelo seleciona-se um algoritmo, o qual resulta em um sistema e finalmente uma aplicação.
O processo de modelagem é cíclico e cada interação aumenta a qualidade dos resultados. A partir da concepção de novos modelos e a escolha de algoritmos eficientes, melhora-se a expressividade dos modelos. Os algoritmos aplicados aos sistemas melhora a utilidade dos padrões (expressa um comportamento de maior valor para o negócio). Sistemas e aplicações mais elaborados incrementam a escalabilidade e eficiência. Por último, os melhores modelos e aplicações proporcionam maior relevância aos resultados apresentados.
No quadrante aplicações, um dos usos mais destacados são os de incorporação de modelos de análise aos sistemas tradicionais (embedded analytics) e inteligência artificial na construção de plataformas digitais, tais como: painéis e visualizações de dados em gráficos que exibem métricas de desempenho e relatórios com informações tabulares, autoatendimento e consultas ad hoc, funcionalidades interativas em dispositivos móveis, sistemas de recomendação, sistemas de reputação, dentre outros.
Conclusões
Apontada como uma das 10 profissões mais requisitadas em 2017, a ciência de dados tem ganhado destaque nos últimos anos. Este artigo apresentou o perfil e competências necessárias para os profissionais que almejam atuar nessa área tecnológica. Além disso, apresentou os processos executados por esses profissionais. Por último, é importante destacar que tudo sobre ciência de dados está em constante mudança graças ao impacto da tecnologia na capacidade de analisar grandes volumes de dados.
Referências
1. Stewart Tansley; Kristin Michele Tolle (2009). The Fourth Paradigm: Data-intensive Scientific Discovery. Microsoft Research. ISBN 978-0-9825442-0-4
2. Data Scientist: The Sexiest Job of the 21st Century, https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century – Último acesso em Novembro de 2017.
3. A Very Short History Of Data Science – Forbes, www.forbes.com/sites/gilpress/2013/05/28/a-very-short-history-of-data-science/ – Último acesso em Janeiro de 2017.
4. Notas de aula da disciplina Mineração de Dados, ministrada pelo professor Wagner Meira no programa de pós-graduação em ciência da computação da Universidade Federal de Minas Gerais.
Sérgio Mariano Dias
É Doutor (2016) e Mestre (2010) em Ciência da Computação pela UFMG e Bacharel em Ciência da Computação pela PUC Minas (2007). Atualmente, trabalha na “Divisão de Soluções Analíticas no Data Lake”, como cientista de dados, e no programa de pós-graduação em informática da PUC Minas, como pesquisador em pós-doutorado no tema ciência de dados. Interessado em pesquisa aplicada, gosta de aprender e integrar governo, sociedade e indústria. Website: http://sergiomdias.com
Dados de Governo
Conheça a plataforma de APIs do Serpro, solução para consumo de dados governamentais diretamente das bases da empresa guardiã desse conteúdo. A plataforma oferece rapidez, segurança e confiabilidade, garantindo a exibição de dados atualizados em tempo real. Acesse: https://servicos.serpro.gov.br/api-serpro/
Fonte: SERPRO
Leia também: Entrevista com presidente do SERPRO
