
Falar sobre esse assunto é muito difícil quando não se tem uma boa compreensão de que cada informação tem um valor diferente para cada indivíduo, mas que existem informações que são de senso comum quanto ao seu maior ou menor valor.

William Telles
Por William Telles
Em tempos de GDPR, Lei 4060/2012, novos termos como “dados sensíveis” e “dados identificáveis”, é fundamental que tenhamos em mente que não dá mais espaço para tratarmos toda informação como qualquer informação, ou como alguém já disse: “confundir Capitão de Fragata com Cafetão de Gravata”!
Por que damos maior proteção a nossa senha de contas bancárias, do que aos demais dados da conta(Banco/Agência/Conta)? Porque a senha é a chave com a qual abrimos a porta da nossa conta bancária para movimentação financeira. Mas se senha pode ser comparada a uma chave, por que não se tem o mesmo zêlo com as senhas de outros serviços ou recursos? Por exemplo, por que senhas de sistemas de informação são frequentemente registradas em locais que qualquer um possa ter acesso?

Além de, sem dúvida, existir um problema sério de conscientização sobre a importância de proteção aos dados e informações que manuseamos dentro das organizações, ainda há quem não se preocupe com o vazamento de dados vitais ao negócio, por não ter passado (ainda!) por vergonha e exposição pública negativa como o Facebook!
A questão é: aguardar até que o problema ocorra para começar a cuidar melhor das informações que lidamos diariamente em nossas organizações, ou “arregaçarmos as mangas” e começarmos a pensar preventivamente na proteção dos nossos ativos de informação? Uma coisa eu posso garantir: o investimento (não é custo, ok?!) é bem menor do que tratar um problema dessa envergadura de ocorrido.
É possível que muitos projetos de classificação da informação tenham ficado apenas na planilha de rascunho por falta de direcionamento especializado para tocar a iniciativa adiante. Se for isto, vejamos se com este artigo é possível ajudar!
De acordo com a norma ISO 27001, a classificação de uma informação deve seguir o seguinte roteiro:
-
Inventário de Ativos de Informação
Antes de mais nada, lembre-se que uma empresa possui diversos processos de negócio, por onde circulam várias informações o tempo todo. É muito difícil iniciar um trabalho de prevenção à perda de dados, sem antes classificar as informações que circulam pelos processos de negócio; e é muito mais difícil classificar informação quando na maioria das vezes não somos os “donos” da informação.
Aproveitando a máxima “quem calça o sapato é quem sabe onde o calo aperta”, são os gestores de áreas de negócio quem (quase sempre) sabem quais informações são vitais para o negócio; mas como são várias áreas em uma organização, como ter um ponto central para a gestão da informação? Resposta: tendo um Inventário de Ativos de Informação.
É possível que você tenha tentado fazer um inventário completo de ativos e não conseguiu, incluindo junto com os ativos de informação, ativos físicos, ativos de software, ativos intangíveis, etc. Ok, mas sem um inventário de ativos de informação, será muito mais difícil identificar os proprietários de ativos, informação vital para seguir com a Classificação da Informação.
Assim sendo, pegue o organograma hierárquico de sua empresa, mapeie as áreas de negócio, e mãos à obra: converse com cada gestor de área, entendendo quais informações são manuseadas pela sua área, quais são criadas a partir de sua área, e qual o nível de importância para o negócio dessas informações (qual informação, para que serve, quem manipula, e quais consequências da manipulação por pessoas não autorizadas, etc). Se quiser, pode usar algo parecido com o exemplo abaixo:
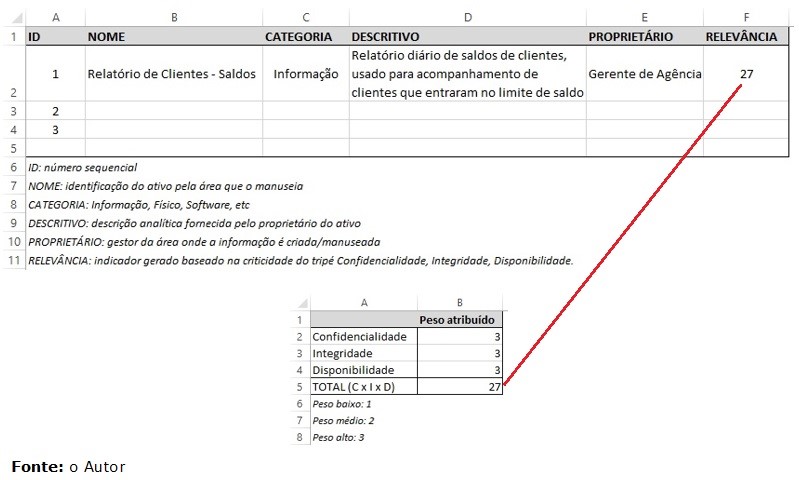
-
Classificação da Informação
De posse do inventário de ativos de informação, pode-se começar a classificação das informações inventariadas.
De acordo com a ISO 27002:2013:
“Convém que a classificação e os controles de proteção, associados para a informação, leve em consideração as necessidades do negócio para compartilhar ou restringir a informação bem como os requisitos legais. Convém que outros ativos além dos ativos de informação também sejam classificados de acordo com a classificação da informação armazenada, processada, manuseada ou protegida pelo ativo.”
Considerando a orientação acima, é perfeitamente possível entender que a classificação da informação poderá seguir tantos quantos níveis de classificação a complexidade do negócio exija, mas vias de regra, os níveis mais comuns de Classificação da Informação são:
- CONFIDENCIAL: o impacto aos objetivos estratégicos e as consequências do acesso não autorizado à esta informação são severos e, possivelmente, irreversíveis.
- RESTRITO: impacto menor, mas consequências relevantes.
- USO INTERNO: constrangimento é maior que o impacto e suas consequências.
- PÚBLICO: o acesso é permitido à qualquer pessoa, sem impacto ou consequências ao negócio
Item à item, você deve incrementar uma coluna na planilha acima apresentada, que conterá a informação de nível de classificação da informação, conforme abaixo:

É necessário lembrar neste momento que deve haver alguma coerência entre a RELEVÂNCIA e a CLASSIFICAÇÃO da informação. No exemplo acima, a relevância teve o maior valor possível determinado durante o inventário de ativos de informação, mas na hora da classificação foi atribuído um valor abaixo do que seria o equivalente à relevância. Para que haja coerência no exemplo acima, a classificação deveria ser CONFIDENCIAL.
Em havendo dificuldade em criar relação de equivalência entre estes 2 domínios, pode-se automatizar o processo de classificação da informação criando uma planilha de equivalência conforme o exemplo abaixo, e validar com os gestores entrevistados à época do inventário: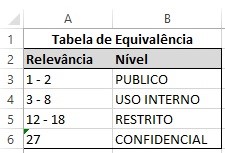
Após a conclusão das atividades acima, é possível agora buscar no mercado uma ferramenta de DLP (Data Loss Prevention), se possível, que já integre a funcionalidade de rotulagem da informação, com APIs de integração aos aplicativos de edição/geração/movimentação de documentos.
Você até poderia dizer que hoje existem ferramentas de DLP que já possuem maior integração com a classificação de dados, identificando, por exemplo, arquivos confidenciais no momento em que são criados, ou o conteúdo confidencial dentro de imagens (OCR). É verdade, mas sem a criação de consciência e de processos específicos, não será possível, sequer, acabar com os “post its” debaixo do teclado…quanto mais trabalhar de forma corporativa a prevenção à perda de dados.
Sucesso, bom trabalho, e mãos à obra!
William Telles Consultor Sênior – Segurança da Informação at Sysuni Tecnologia da Informação
